Sweep's Core Algorithm - Using Retrieval Augmented Generation (RAG) to clear your GitHub Backlog
Kevin Lu - August 9th, 2023
At Sweep, our core issue-to-pull-request pipeline resolves around an RAG-based pipeline. This means we retrieve snippets from a corpora (your codebase) and feed it to a language model (GPT-4) to generate code.
In summary, Sweep searches for relevant files and edits the file(s) it thinks requires changes. Sweep then validates its own changes by reading for logical errors and running GitHub Actions on them and finally leaves the pull request for the user to review.
The following is the Sweep’s pipeline that turns an issue like “the app has an error relating to temporary directories on Windows” into a pull request titled “replace all occurrences of /tmp with tempfile.TempDirectory()” like this (opens in a new tab).

Inputs
Everything starts with the inputs, including everything in the following:
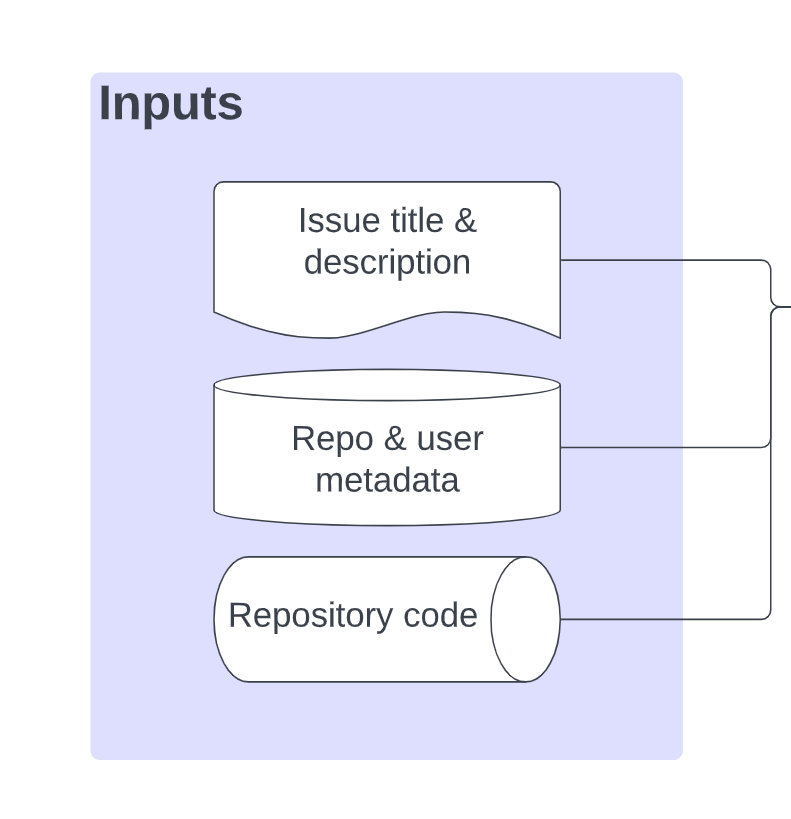
Only the issue, repository and user metadata are useful for now. The context fed to the language model at this point looks like this:
Repo name: sweepai/sweep: an AI junior dev
Username: kevinlu1248
Query: Sweep: Use os agnostic temp directory for windowsThe next step is to use the codebase, but codebases can have up to thousands of files! Thus, we only search for relevant files.
Search
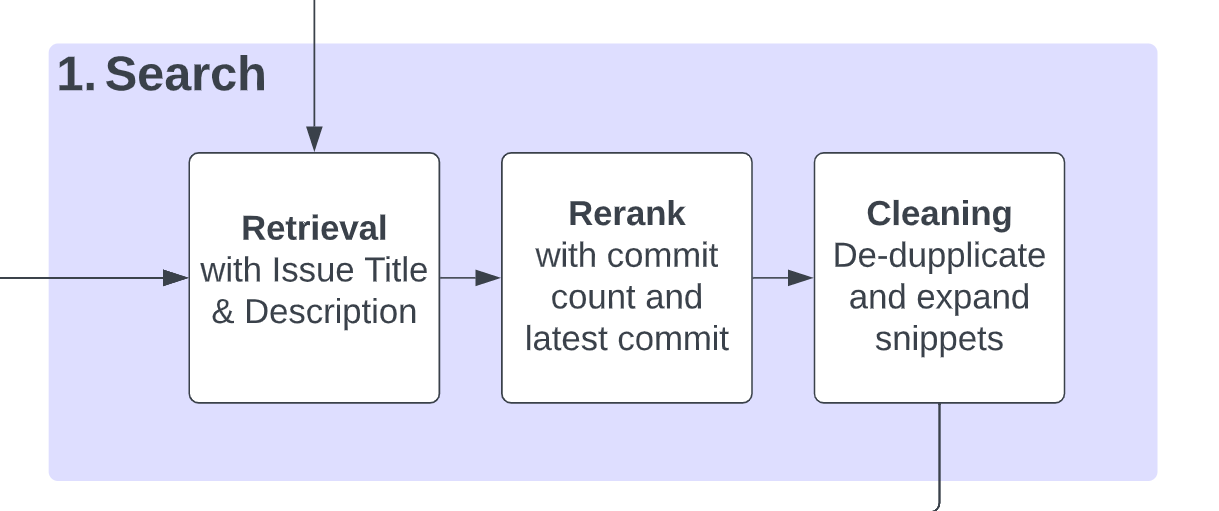
Sweep starts searching for relevant snippets by:
- Query the title and description against the code snippets as the context and retrieves the top 100 snippets using MPNet (opens in a new tab) embeddings and a DeepLake (opens in a new tab) vector store. We chunk the files ahead of time using a custom CST-based chunker (opens in a new tab). We have a more details tour of our search infrastructure at https://docs.sweep.dev/blogs/search-infra (opens in a new tab) and https://docs.sweep.dev/blogs/building-code-search (opens in a new tab).
- Re-rank the snippets using a heuristic based on the commit count and time of the latest commit and pick the top 4. The assumption is that the files with the latest commit and highest commit counts are more likely to be edited again. We also at this point add any files mentioned directly.
- De-duplicate and fuse snippets. For example, if the snippet
main.py:0-50andmain.py:51-100gets fetched, they get fused intomain.py:0-100. We then extend each snippet by 25 lines in each direction, somain.py:25-75becomesmain.py:0-100. - Generate a summary of the repository using ctag summaries (opens in a new tab) of the top 10 files from the re-ranking, which is a summary of the variable names and functions declared in the file. This is presented as a directory tree: starting from the root directory all the way to the files and the classes, methods and variables of the files. Only files that are siblings of the top 10 files will be
The final context at this point looks something like the following:
<relevant_snippets>
<snippet file_path=”main.py” start_line=”1” end_line=”56”>
import numpy as np
...
</snippet>
<snippet file_path=”test.py” start_line=”1” end_line=”32”>
import pytest
...
</snippet>
...
</relevant_snippets>
<repo_tree>
.gitignore
jp-app/
|- App.xaml
|- App.xaml.cs
| |- namespace jp_app
| |- class App
| |- method App (ISystemLanguageService systemLanguageService)
| |- method OnStart ()
</repo_tree>
Repo name: sweepai/sweep: an AI junior dev
Username: kevinlu1248
Query: Sweep: Use os agnostic temp directory for windowsExternal Search
On top of the code snippet search, we also perform external search:
- Public websites: leaving a link to a publicly accessible site will make Sweep read the contents of the page.
- Documentation search: GPT-4, unfortunately, has only been trained until 2022 so it won’t have access to the latest docs, so we set up search indices for docs that update once a day. The current list of docs that get indexed can be found at https://github.com/sweepai/sweep/blob/main/sweepai/pre_indexed_docs.py (opens in a new tab), and we’ll write another post describing how we fetch the docs soon. Feel free to create a PR to add docs you would like to see Sweep use!
Planning
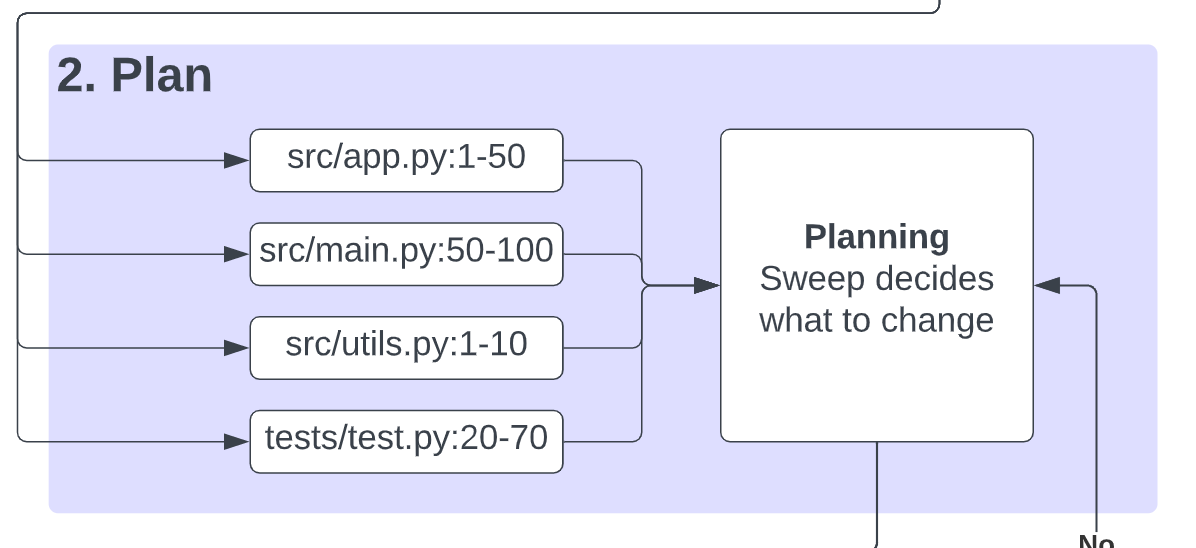
Sweep then curates a list of files it wants to modify and those it wants to create by:
- Determining what the root causes of the issues are. E.g. the bug has to do with
/tmpnot existing on Windows. - Determining in natural language an implementation plan using chain-of-thought prompting. E.g. replace all occurrences of
/tmpwithtempfile.TemporaryDirectory(). - Specify a list of files to modify, like the following:
<modify_file>
* filename_3: instructions_3
* filename_4: instructions_4
...
</modify_file>
<create_file>
* filename_1: instructions_1
* filename_2: instructions_2
...
</create_file>We then validate these suggested changes, by changing any “modify”’s to “create” if the files don’t exist and vice versa. In the future, we can use a fuzzy algorithm since we’ve noticed that Sweep sometimes says it wants to modify src/components/NavBar.tsx when only the file src/components/Navbar.tsx exists (capitalization error), or similar errors for slightly incorrect paths.
Execution
Sweep creates each file from scratch (in the case of file creation) or determines which lines it wants to modify. Modification is drastically more complex and involves:
- Creating a high-level game plan of what in particular to change. E.g. Use an OS-agnostic alternative to
/tmpdirectories by using Python’stempfile.gettempdir(). - Identifies all locations of it and creates a list of natural language descriptions of changes with reference to line numbers. E.g. In
sweepai/app/ui.py, in theget_repo()function replace all occurrences of/tmptotempfile.gettempdir(). - Generate search-and-replace pairs, using a format (opens in a new tab) based on
aider’s prompts, another open-source LLM-powered devtool. This looks something like the following:
<<<< ORIGINAL
x = 1 # comment
print("hello")
x = 2
====
x = 1 # comment
print("goodbye")
x = 2
>>>> UPDATEDWe use fuzzy matching for the “search” part of “search-and-replace”, based on heuristics like equal start lines and end lines, since GPT-4 skips comments in the “ORIGINAL” section.
For larger files (>1000 LOC), we use a streaming method, involving feeding in 600 lines of code at a time (which corresponds to about 15k tokens).
Validation
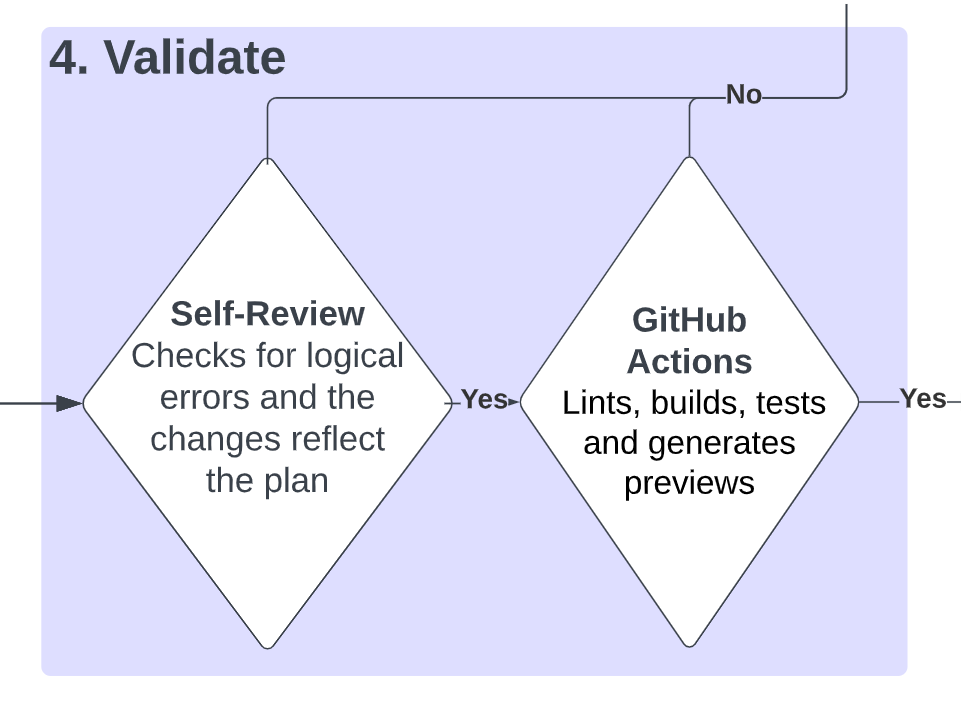
We run both an LLM-based and procedural validation to ensure that there are no errors in the new code and that the generated code reflects the changes summarized by the pull request.
If changes are needed, we re-run the pipeline on the pull request from the beginning, with a few additions. We always include as part of the search all the files that were modified as part of the pull request and we skip the self-review.
Self-Review
Sweep checks the code diffs and the pull request summary using GPT-4 and verifies that nothing is clearly broken. If something is broken, Sweep makes a comment on its own pull request with a summary of things to change.
If it fails again, we do another self-review. We iterate for a maximum of three times.
GitHub Actions
GitHub Actions is used to check for errors such as type errors, compile-time errors and failed test runs. Failed Action logs get fed to Sweep and get treated like pull request comments.
This is entirely configurable by developers. We use GitHub Actions since there’s a plethora of tools it can use and most developers have GitHub Actions already set up for their team. See more at https://docs.sweep.dev/blogs/giving-dev-tools (opens in a new tab).
User Review
When a user leaves a comment on the pull request, we re-run the entire pipeline, similar to Sweep’s self-reviews or failed GitHub Action runs.
For code comments, Sweep skips to the execution step and only modifies the file the code comment was left on. This is significantly faster, although the scope is limited.
Once again, here’s the final pipeline.
⭐ If this interests you, see our open-source repo (opens in a new tab)!