AI-powered junior dev meets Trunk, a super-linter
Kevin Lu - Oct 4th, 2023
Even with all our fixes to enforcing GPT-4 to write high-quality edits to code, we still end up with code that doesn’t build, or even parse at times.
This is because when GPT-4 is focused on editing some snippets of code, it's hard to tell while editing whether the updated code will result in undefined variables or type errors, much less unused variables or imports. What’s worse is GPT-4 can't even identify faulty code sometimes with undefined variables or erroneous typings, especially involving imports from other files.
Thus, the only solution is to give Sweep dev tools normal engineers have access to -- linters and type checkers.
The tools
Linters
What we found previously from using ChatGPT is that it can generally explain what to fix given the code and the error logs.
Further, a common case is also that the modification algorithm would edit two parts separately and result in missing open or closing parentheses, ultimately yielding a syntax error. Another case is where Sweep adding import statement succeeded but actually using the imported library failed, which results in an unused import. For both of these cases, a linter like eslint would catch the error.
We ended up with the following prompt. We ended up using the aider diff prompt since it was more reliable for small-scale changes compared to our new search-and-replace mechanism.
System message
You are to identify the problem from the error logs and fix the code. You will respond in the following format:
Code Planning:
What does the error log say? Where and what is wrong with the code? What should you do to fix it?
Detailed plan of modifications:
* Replace x with y
* Add a foo method to bar
...
Code Modification:
Generate a diff based on the given plan using the search and replace pairs in the format below.
* Always prefer the least amount of changes possible, but ensure the solution is complete
* Prefer multiple small changes over a single large change.
* NEVER write ellipses anywhere in the diffs. Simply write two diff hunks: one for the beginning and another for the end.
* DO NOT modify the same section multiple times.
* Always add lines before and after. The ORIGINAL section should be at least 5 lines long.
* Restrict the changes to fixing the errors from the logs.
The format is as follows:
Hunk description:
<<<< ORIGINAL
second line before
first line before
old code
first line after
second line after
====
second line before
first line before
new code
first line after
second line after
>>>> UPDATEDUser message
File Name: {filename}
<old_file>
{code}
</old_file>
---
Above is the code that was written by an inexperienced programmer, and contains errors. The CI pipeline returned the following logs:
<stdout>
{stdout}
</stdout>
Instructions:
1. Complete the Code Planning step
2. Complete the Code Modification stepThis prompt can be found in https://github.com/sweepai/sweep/blob/main/sweepai/sandbox/src/prompts.py (opens in a new tab).
This seems to recover most broken code like unused variables but not syntax errors. Unfortunately, eslint's error message only says“unexpected token” with the line number. The last blog on modifying code with GPT-4 can tell you how much GPT-4 loves line numbers.
For example, when getting Sweep to migrate React components (opens in a new tab) from function components to class components, a common error is a missing closing parenthesis at the end of the file. This is because GPT-4 generates diffs to edit the start of the component but not the end, which results in a missing closing parentheses at the end, yielding the following unhelpful message:
# npx eslint src/App.tsx
/home/kevin/sweep-landing-page/src/App.tsx
139:0 error Parsing error: '}' expected
✖ 1 problem (1 error, 0 warnings)Formatters
There are two main reasons we use formatters:
- Formatted code is easier to fix. Bad indentation is very hard to read even for humans.
- As indicated earlier, formatters tend to give better error messages for syntax errors.
For example, here’s the equivalent error message for the same error from prettier.
# npx prettier src/App.tsx
src/App.tsx
[error] src/App.tsx: SyntaxError: '}' expected. (139:1)
[error] 137 | );
[error] 138 |
[error] > 139 |
[error] | ^As you can see, prettier error logs indicate mistakes significantly clearer. We run this before running linters to ensure that parseable, formatted code is fed to GPT-4 to handle linting errors.
Type-Checker
What’s the point of writing Typescript if we don’t type-check? The last piece to the puzzle is running tsc. The most frustrating thing is when all the changes look about right but Netlify wouldn’t deploy the website preview because there’s an implicit-any.
Orchestration
So what exactly should Sweep run? We ended up settling on the following iteration loop:
- For every command in the list
prettier,eslintandtsc, try running them. - If it succeeds move on to the next command.
- If it fails, get GPT-4 to fix it based on the above prompt and go back to step one with
prettier.
Iterate this for a maximum of 15 times. We found that it many times it would fix everything around the 10th iteration, so we put max 15 just to be safe.
We go back to prettier because sometimes writing a diff to fix eslint or tsc breaks the syntax once again. It’s like climbing a very shaky latter: every time you fall you go back to step 1. It's like playing a platformer with one life: every time you die you go back to the beginning.
Generalizing
This is amazing, but how do we do this much tuning for every single user? Most users will not use Sweep sandbox if high-quality results depend on significant configuration.
However, configuring for every use case is extraordinarily difficult. There are dozens of languages each with dozens of associated tools. Just Python alone has like 15 linters.
Trunk
We found Trunk at around this time, a super-linter. Think Swiss army knife for formatters, linters and more.
On installation, it installs a handful of the most commonly used formatters, linters and dev tools for the repo, like eslint for JS/TS and ruff for Python, along with maybe 5 other compatible formatters and checkers.
For example, to set this up for our system above, we can generalize prettier to trunk fmt and eslint to trunk check.
Another frustration of linters is that when you install them, most linters by default reveal dozens of errors per file, of which most are nit-picks like lines being too long. Trunk gets around this by reporting only newly generated errors: that is, errors in the git diff that are not in the main branch. Further, Trunk only reports files edited in the feature branch or uncommitted code, eliminating any errors made by other programmers or previously in the codebase.
Trunk is also extremely configurable and easy to install by users, at https://docs.trunk.io/get-started (opens in a new tab).
We decided to use Trunk as the default formatter and linters to use for Sweep sandbox.
Straight into Production
But how do we run this in production, with various different environments and enabling configurability?
Originally we considered just running user’s GitHub Actions on our end but this poses some problems:
- You can’t isolate the run to just one file. Sometimes other parts of the system are broken.
- The only open-source runner is
act(https://github.com/nektos/act (opens in a new tab)) which has yielded many runtime issues for us. - GitHub Actions is too slow. Many simple runs like running
pylintoreslinttake minutes and some testing frameworks can take hours. - GitHub Actions is hard to set up, impossible to test locally, and unintuitive. You need a 50-line GitHub Action yaml just to run
black.
Thus, we set up a Dockerized sandbox environment. Think stripped down GitHub Actions environment: just a setup install script and some way of checking a particular file.
Our default configuration for installing and executing Trunk looks something like
sandbox:
install:
- trunk init
check:
- trunk fmt file_path
- trunk check file_pathExtremely straightforward. The curly brackets allow injecting the currently modified file really easily. We can cache the container after the install scripts finish too to optimize the startup speed.
Here are some other examples. Our setup at Sweep installs and runs pre-commit and pylint through poetry. The second line checks that it’s a Python file before executing. The sandbox config on our landing page runs prettier, eslint and tsc for JS/TS files.
Sweep's config
sandbox:
install:
- pre-commit install
- pip install poetry
- poetry install
check:
- pre-commit run --files {file_path}
- '[[ "{file_path}" == *.py ]] && poetry run pylint --errors-only {file_path} || exit 0'Sweep landing page's config
sandbox:
install:
- yarn install
check:
- yarn run prettier --write {file_path}
- yarn run eslint --fix {file_path}
- yarn run tscWe run this on an ubuntu image with the default configurations installed. We originally tried this on debian-buster but ended up with too many environment errors with switching Python versions. You can find this image at https://hub.docker.com/r/sweepai/sandbox (opens in a new tab) and feel free to extend it at https://github.com/sweepai/sweep/blob/main/sweepai/sandbox/Dockerfile.sandbox (opens in a new tab).
Now we just need to address the last problem: local testing. I ended up making a Python script that
- Pulls the docker image and spins it up.
- Copies the local file system into the container.
- Executes the “install” and “check” scripts.
Initially, I had the user define the “{file_path}” but most users got confused so now it just defaults to the last edited file in the git history. I bundled this into an installation script using PyInstaller to turn it into a binary executable at https://github.com/sweepai/sweep/blob/main/bin/install_sweep_sandbox.sh (opens in a new tab). You can run this installation script with
curl https://raw.githubusercontent.com/sweepai/sweep/main/bin/install_sweep_sandbox.sh | shInterface
An initial issue with Sandbox is that it wasn’t clear to most users what was running. In fact, most users didn’t even know whether it was even running. Letting users know what’s happening also allows them to tune the Trunk configurations to not run any unwanted formatters, for example.
After a few iterations, we settled on the following.
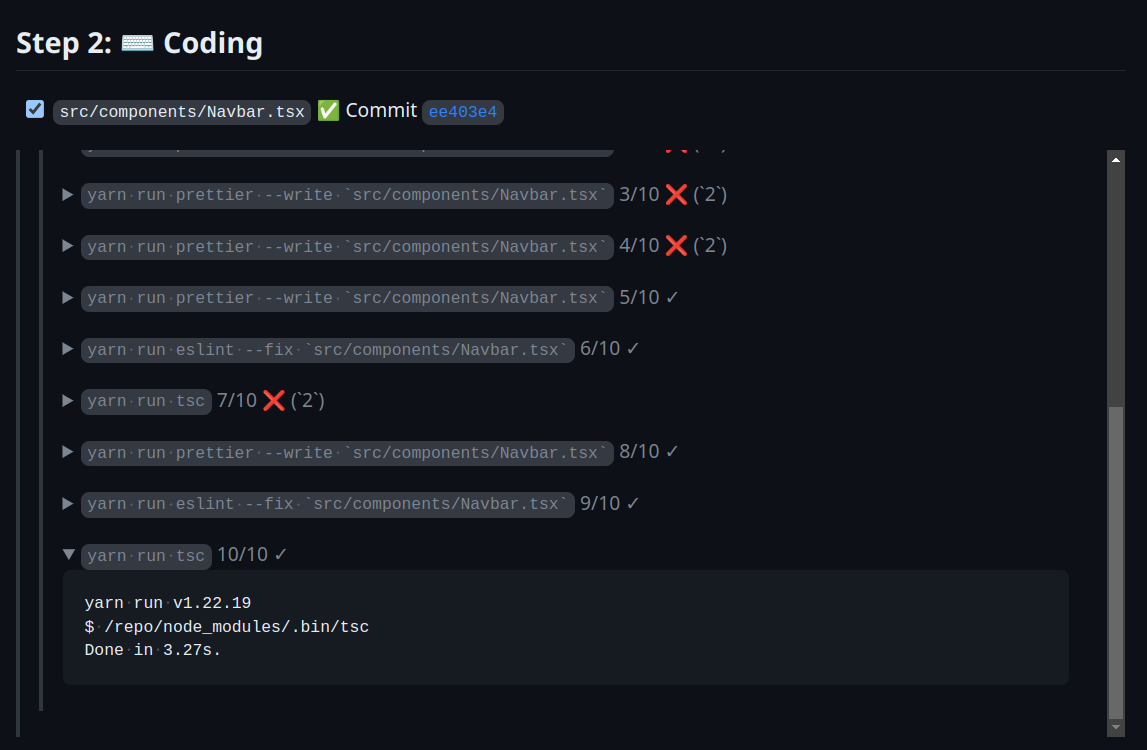
Example can be found at sweepai/landing-page#481 (opens in a new tab).
We decided to collapse all execution logs but the last. We gave failures a big red X with the error code, but success cases will have an uncolored checkmark.
In the future, we could also add intermediate diffs to show what Sweep changed as a consequence of each set of logs for transparency. This allows users to inspect what went wrong and provide high-quality feedback. We could also batch the executions for cleanliness so we don’t have 20 executions since prettier is executed every time.
If this sounds interesting to you, configure Sandbox for your Sweep repo at https://docs.sweep.dev/usage/sandbox (opens in a new tab) and join our community at https://community.sweep.dev/ (opens in a new tab) if you have any questions or suggestions!